Built-in Functions
這是一系列關於我拿到天文碩士學位,我一路所學到的技能,以及我認為必須延伸的技能組的文章,技能主線會保留在Medium上,以中英文方式呈現,而技能支線,會以中文形式在GitHub.io,也就是這裡發表。
預計兩邊加起來會有27篇文章,透過這些文章來檢核天文學位帶來給我哪些影響。
前言
這篇文章假設你已經安裝好Python,並且能夠Compile your code,如果還不清楚,建議先閱讀Starting Python。
Built-in Functions
如標題所寫,今天會先了解到Python本身內建的函數,使用這些函數可以更快的編譯,減少呼叫外在套件達成一樣目的的時間。
A*
abs()
Short for absolute. 絕對值
回傳數值的絕對值,如果輸入為複數,則回傳magnitude.
1 |
|
all()
From documentation:
Return True if all elements of the iterable are true (or if the iterable is empty)
1 | def all(iterable): |
從官方解釋其實很好理解了,只要你的list裡面或是可迭代的物件裡面,全部不為空值,則回傳True。
我們可以藉由一些例子來更好理解,也可以判別None,np.nan這些物件會被判別成怎樣
1 |
|
any()
any是跟all 相反的一種模式,只要迭代物件裡面任一是有值,就會回傳True
From documentation:
1 | def any(iterable): |
1 |
|
B*
bool()
回傳boolean ,布林值, True or False,與any(),all()類似。
1 |
|
breakpoint()
在Python3.7 之後,新增了breakpoint的功能,過往在debug,通常都是透過print來了解變數值,或者了解函數進行到哪個階段,或是透過IDE有的debug功能,去設定breakpoint的點,這些功能現在可以透過給breakpoint()來達成。
如果是對於使用debug不熟悉的人,建議可以觀看CS50 Lecture2,關於debugger的用法與操作。
breakpoint()可以想像是一個暫停點,程式會在breakpoint處停下來,你可以檢視目前的變數值等等。
舉個例子,這以下的迴圈當中,i的值也許很好判斷,那j的值已經跑到哪裡了,也許是我們有興趣的
1 | for i in range(10): |
1 |
|
如果有經驗,可能一眼就看出這個迴圈有問題,然而一開始沒經驗,可能會想說j怎麼沒有一直加上去,然後最後output出來就完全抓不到bug在哪裡。此時設立breakpoint,就可以知道每跑一次迴圈,數值的變化如何,那問題點會在第一個或是第二個回圈裡面。
從code裡面,我們看到了(Pdb),也就是當遇到breakpoint()時,Python會叫出了指令,在這個環境下,可以對於參數進行檢核,像我們使用print()的方式,那麼要進到下一個breakpoint(),或者其他操作,有相對應的指令:
- 看變數值:
p [var] - 看目前位置:
l - 繼續到下一個breakpoint():
c - 離開:
q
當中還有其他指令,不過這些就足以應付大部分debug的需求了。
D*
delattr()
在講到Class之前,我們先講到如何刪除屬性。由於Python語法是基於物件導向,任何東西都是視為一個物件在處理,類別(Class)也不例外,所以類別就會有屬性(attribute)。
舉個例子,
一個立方體的類別我們叫做cube,那立方體有的就是三邊的邊長,我們各自叫x,y,z,我們呼叫一個a為一個立方體,那他有三個屬性就分別是x,y,z,我們可以透過a.x, a.y, a.z來檢視a的屬性。當要刪除x的屬性時,可以使用delattr()。
1 | class cube(): |
delattr(a,'x')也等同於del a.x
dict()
dict 為字典類別,用法類似於list(), set(),會創造出一個字典物件。
根據官方文件指出,底下6種方式皆可以創造出{"one": 1, "two": 2, "three": 3}。
1 | a = dict(one=1, two=2, three=3) |
從其中幾種方式不難看出,在創建字典物件時,內建的dict()並不是必須,單純的使用{} 就可以創立字典物件。但在多個list物件時,或是要用zip將list合併成字典時,dict()會是更好用的選擇。
dir()
dir()提供the list of names in the current local scope。
這句話有點難翻譯,白話文的意思是回傳當下本地的變數範圍。
簡單的不同範例應該可以更好理解,在沒有給參數的python檔案裡面,我們直接print(dir()),會得到一串變數名稱,如果針對個別變數去看他的值,不能看出這是在跑檔案時他本身的資訊。
這邊特別去print __name__這個變數,這個變數會在很多Python裡面看到,以
if __name__ == __main__的形式。
1 | print(dir()) |
divmod()
處理division除法的函式,可搭配下方語法糖做合併閱讀。
divmod()會回傳quotient, remainder,而語法糖都只回傳數值。
1 |
|
1 | import math |
F*
filter()
filter()顧名思義會做濾除的動作,依照判斷式來回傳一個iterator。
1 | a = [1,2,3,4,5,6,7,8] |
I*
input()
當我們需要使用者輸入參數時,input可以擷取使用者在Terminal裡輸入的內容。
這是非常常使用的函數,畢竟我們不想要隨時hard coding我們的程式,每次都要進入程式碼修改參數。
1 |
|
int()
將字串或浮點數轉換成整數。
這將會在處理檔案數字(通常是字串)或者取整數位時常用。
len()
Len為length縮寫,回傳物件的長度。
物件可以是一個list, tuple, string 或是dictionary.
1 |
|
list()
List的功用很廣,這邊舉幾個例子,主要是可以把一些可迭代物件轉換成list的形式。
以上一個例子來說
1 | dictionary = {"a": "Anal","b":"Breast","c":"Cunt","d":"Dick"} |
map()
Return an iterator that applies function to every item of iterable, yielding the results.
Map就我經驗來說,他是非常好用,但不常用,屬於比較進階,當有些經驗之後,漸漸的map會是手上很好用的工具之一。
以一個例子來說,對於一個list如果需要取整數,勢必要用int取整數值,此時我們可以藉由map將大量數值一併作轉換。
但要注意的是map回傳的並不是list而是迭代器,所以再用list轉換。
1 | print(list(map(int,[1.23,2.24,3.96,4.4,5.95387]))) |
max()
Maximum 顧名思義取最大值
1 | max([1,2,3,4,5]) |
min()
Minimum 顧名思義取最小值
1 | min([1,2,3,4,5]) |
N*
next()
當我們處理到迭代器(iterator)時,next可以迭代到下一個值。
1 | a = iter([1,2,3,4,5]) |
O*
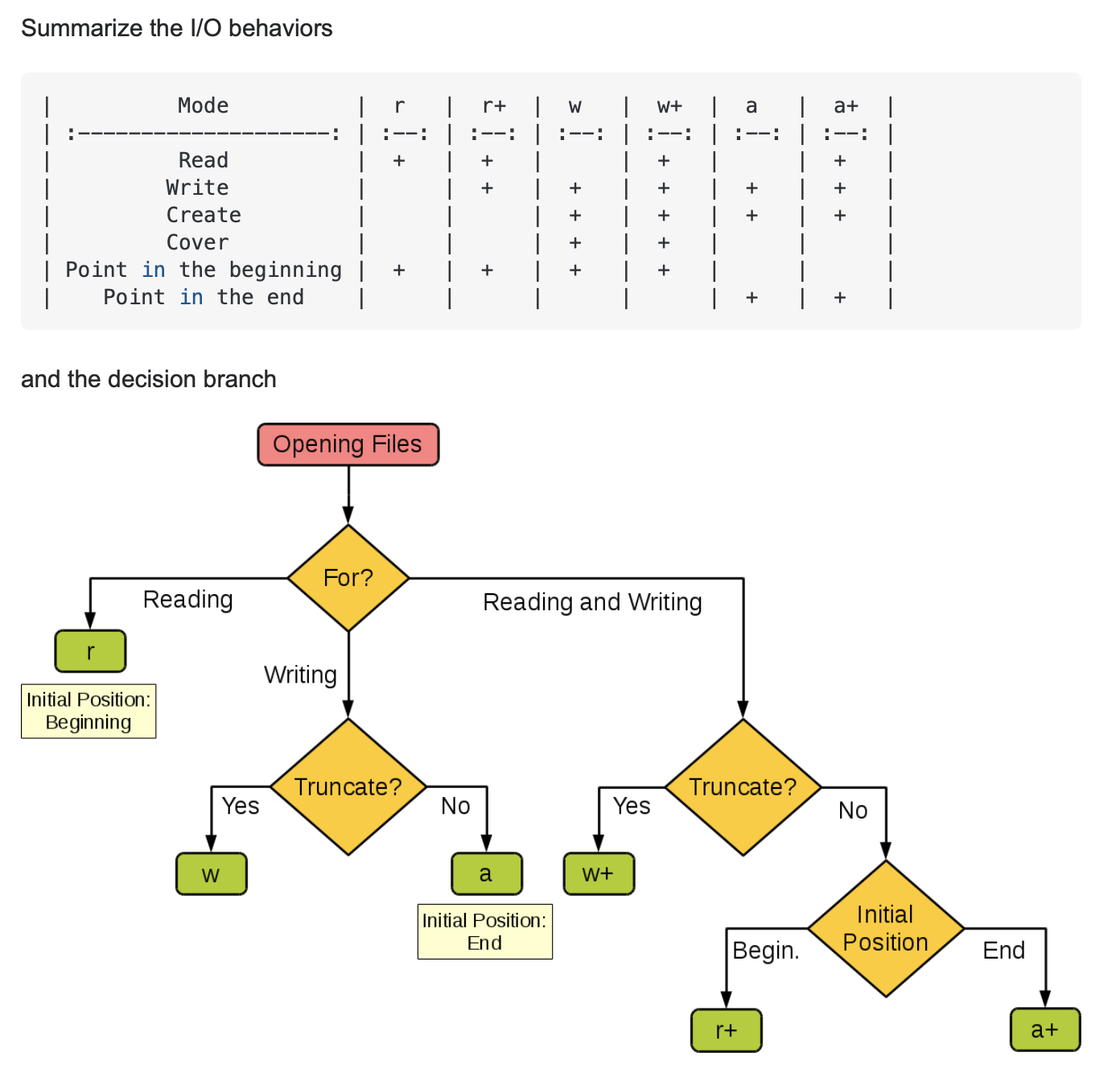
open()
Open 是常常使用來打開檔案的方式,在參數裡面可以選擇打開文件的mode,簡單來說檔案打開並不是直覺的打開而擁有改寫刪的權限,相對的你必須選擇要以哪種方式打開,常用的方式是r,w,a,分別為讀寫以及增加(read, write, append)
通常在打開檔案時,我們會希望資源管理做好,畢竟如果檔案起來,資料讀完,我們想要把檔案關閉把資源拿到該用的地方,所以open常搭配的事with的用法,這樣就不必多寫一行把檔案關閉,也可以避免忘記。
 Someone made this online. Please PM for credit.
Someone made this online. Please PM for credit.
藉由下面的範例我們可以更清楚知道使用方法,在一份sample文件裡面:
1 | This is the first line. |
此時只有使用’r’,所以只能夠讀,並不能寫,如果寫檔案時會出現
io.UnsupportedOperation: not writable
可以在範例裡面看到,讀取檔案有很多種方式,而開啟檔案的f會是一個迭代器,如果要將檔案內容取出當變數,則是要另外給var = f.readlines(), 那麼變數就會是 var = ['This is the first line.\n', 'Second line is about nothing.\n', 'Third line is the end.\n']
1 |
|
當然我們有時候要寫入檔案,此時就要注意選擇的模式會將你的游標放在哪裡,如果是w,游標會在開頭,也就是會將原本內容覆寫過去,如果是a,游標則會在最末端,以添加方式寫進檔案。
要注意的是要換行必須手動給換行符
'\n'
1 | with open('sample.txt','r') as f: |
P*
print()
Print或者任何印出文字的方式,在任何程式語言裡面是Debug相當重要的一環,藉由print出當下的變數值,我們可以更清楚了解目前程式運作到哪一段落,或者變數哪裡出現問題,很多IDE目前有提供Debugger的操作,也是可以藉由暫停程式,查看當下變數值。
R*
range()
Range是一個不變的數列,很常使用在於for loop當中,比如說我要印出1~10,我可以輕易的使用:
1 | for i in range(1,11,1): |
要注意的是range(start, stop, step),stop的值是不會印出來的,所以要多加1上去。
如果想要整個數列,也可以使用list(range(5))來回傳一個[0,1,2,3,4]
round()
round的意思是取整數,所以是進位的意思,在第二個參數可以給要到第幾位。
1 | print(round(2.4)) --> 2 |
S*
set()
set是數一數二常用的函式之一,他會把一個可迭代的物件(list,tuple),回傳一個set,而set裡面不會有重複的值。
1 | a = [1,1,1,2,3,4,5,6,6,4,6,7] |
sorted()
排序迭代物件。
1 | a = [1,1,1,2,3,4,5,6,6,4,6,7] |
str()
string()回傳字串版本的物件,這情況會使用在分析數字時,有時候以字串形式判斷或者要將字串與數字做合併。
不過自從使用f-string之後,這方法就比較少用了。
1 | print('I am '+ str(24) + ' years old') |
sum()
回傳迭代物件的總和。
1 | a = [1,1,1,2,3,4,5,6,6,4,6,7] |
super()
super是一個比較難的概念,多半不會用到,但如果你是進階的使用者,那這項概念就必須了解。
先淺談class的想法,Python語言是物件導向,所以可以想像類別(class)顧名思義是一個族群,那這個族群也會有細分成小族群。
以MLB為例子,MLB是Major League Baseball,美國職棒大聯盟,又可分成國家聯盟與美國聯盟,那麼底下有很多球隊,球隊底下又有不同細部員工。
所以我們可以說MLB是一個類別,底下單一隊伍也是一個類別,但是他們有一些類似的性質存在,比如說都打棒球?(這什麼廢話😂)
當你認為某些功能或行為是subclass也需要時,使用super來繼承
底下這個例子可以看看利用super承接Parent class的功能以及屬性。
1 | class MLB(): |
T*
tuple()
tuple與list,str功用類似,會回傳物件的tuple性質,tuple可以想像成是list的鎖定版本,裡面的值沒辦法做更動,如果要直接寫list可以用[]而要直接寫tuple可以使用()即是tuple物件。
type()
type會回傳物件的類別,有時候不確定物件類別,這是好用的方法。
Z*
zip()
zip也是前三常用好用的函式之一,可以將兩個迭代物件做平行合併。這樣講也許有點抽象,不過我們先看一個例子來了解一下,晚些就知道他的強大。
1 | score = [89,76,83] |
References
Python 3.10.1 Documentation
別再用 print 來 Debug 啦!來用 Python Debugger 吧!
Python 繼承 543